Результаты для "llm benchmarks leaderboard"
LLM Leaderboard 2025 - Vellum AI
https://www.vellum.ai/llm-leaderboard
25 нояб. 2025 г. ... This LLM leaderboard displays the latest public benchmark performance for SOTA model versions released after April 2024.
AI Leaderboards 2026 - Compare LLM, TTS, STT, Video ...
https://llm-stats.com/
Comprehensive AI leaderboards comparing LLM, text-to-speech, speech-to-text, video generation, image generation, and embedding models. Compare performance ...
LLM Leaderboard - Comparison of over 100 AI models from ...
https://artificialanalysis.ai/leaderboards/models
Comparison and ranking the performance of over 100 AI models (LLMs) across key metrics including intelligence, price, performance and speed (output speed ...
Artificial Analysis LLM Performance Leaderboard
https://huggingface.co/spaces/ArtificialAnalysi...
Browse a leaderboard showing performance rankings of various language models. No input is required; simply view the leaderboard to compare different models.
Compare & Benchmark the Best Frontier AI Models - LMArena
https://lmarena.ai/leaderboard
Explore AI model leaderboards to benchmark and compare the best frontier AI ... deepseek-llm-67b-chat. 231. -. 242. 235. 236. 250. 234. 233. yi-34b-chat. 232. 225.
SEAL LLM Leaderboards: Expert-Driven Evaluations - Scale AI
https://scale.com/leaderboard
SEAL LLM Leaderboards evaluate agentic, frontier, safety, and public-sentiment of the latest LLMs. These leaderboards provide insight into models through ...
LLM Benchmarks Leaderboard: DeepSeek, Qwen, Llama
https://lambda.ai/llm-benchmarks-leaderboard
Live leaderboard of LLM results across DeepSeek, Qwen, Llama and more. Compare accuracy and speed to pick models for inference or fine tuning.
LiveBench
https://livebench.ai/
A Challenging, Contamination-Free LLM Benchmark. LiveBench appeared as a Spotlight Paper in ICLR 2025. This work is sponsored by Abacus.AI. Leaderboard
Aider LLM Leaderboards
https://aider.chat/docs/leaderboards/
Aider excels with LLMs skilled at writing and editing code, and uses benchmarks to evaluate an LLM's ability to follow instructions and edit code successfully.
LLM Rankings - OpenRouter
https://openrouter.ai/rankings
Sign up. AI Model Rankings. LLM Leaderboard. Token usage across models on OpenRouter. This Week. Jan 13, 2025 Apr 28 Aug 11 Nov 24 2T 4T 6T 8T.
🖼️ Изображения

LLM Benchmarks in 2024: Overview, Limits and Model Comparison
www.vellum.ai

30 LLM evaluation benchmarks and how they work
www.evidentlyai.com
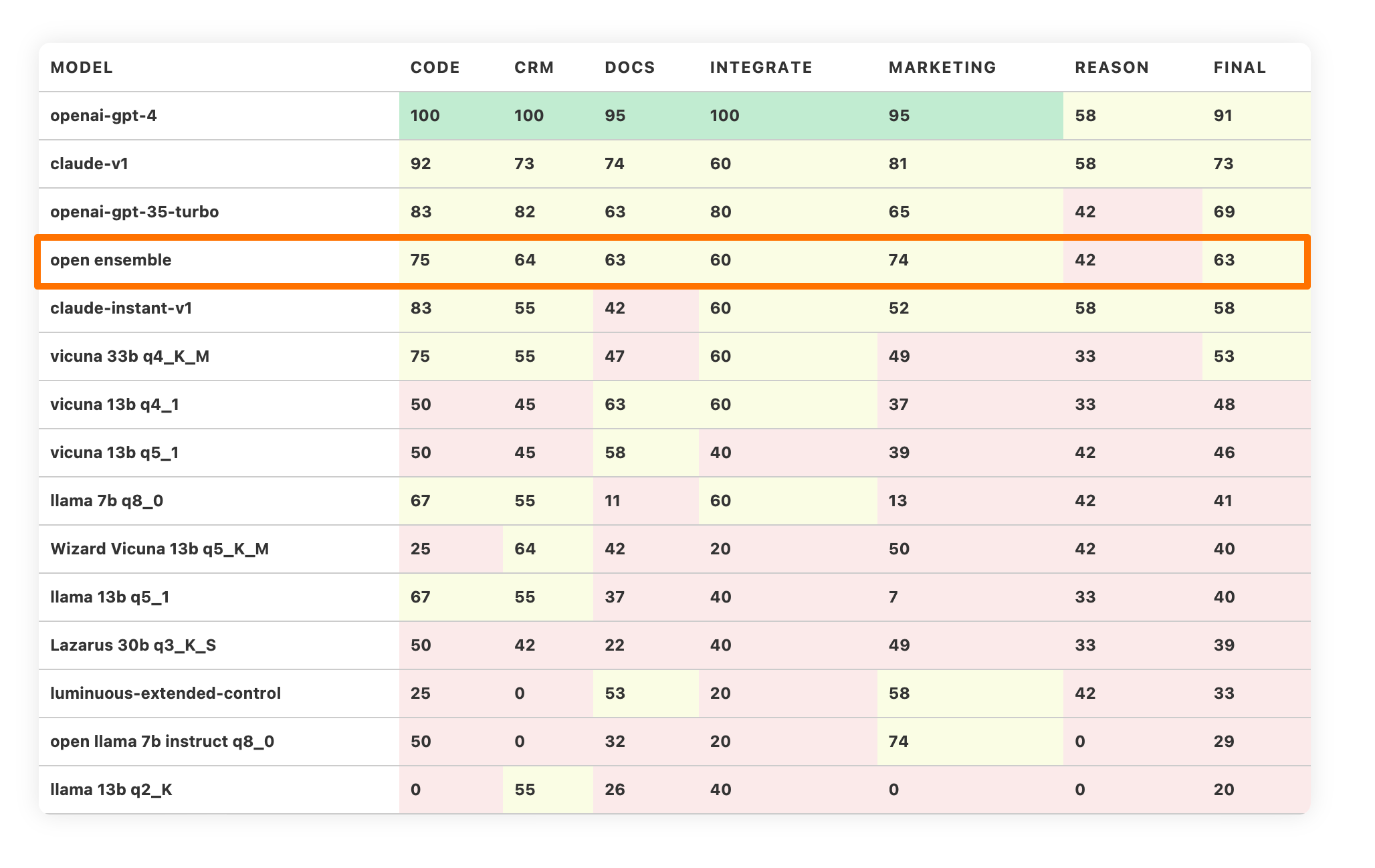
LLM Product Leaderboard: Benchmarks for building and shipping products ...
www.trustbit.tech
Unveiling the Ultimate LLM Benchmarks Guide
blogs.novita.ai

Understanding LLM Benchmarks
www.getcensus.com
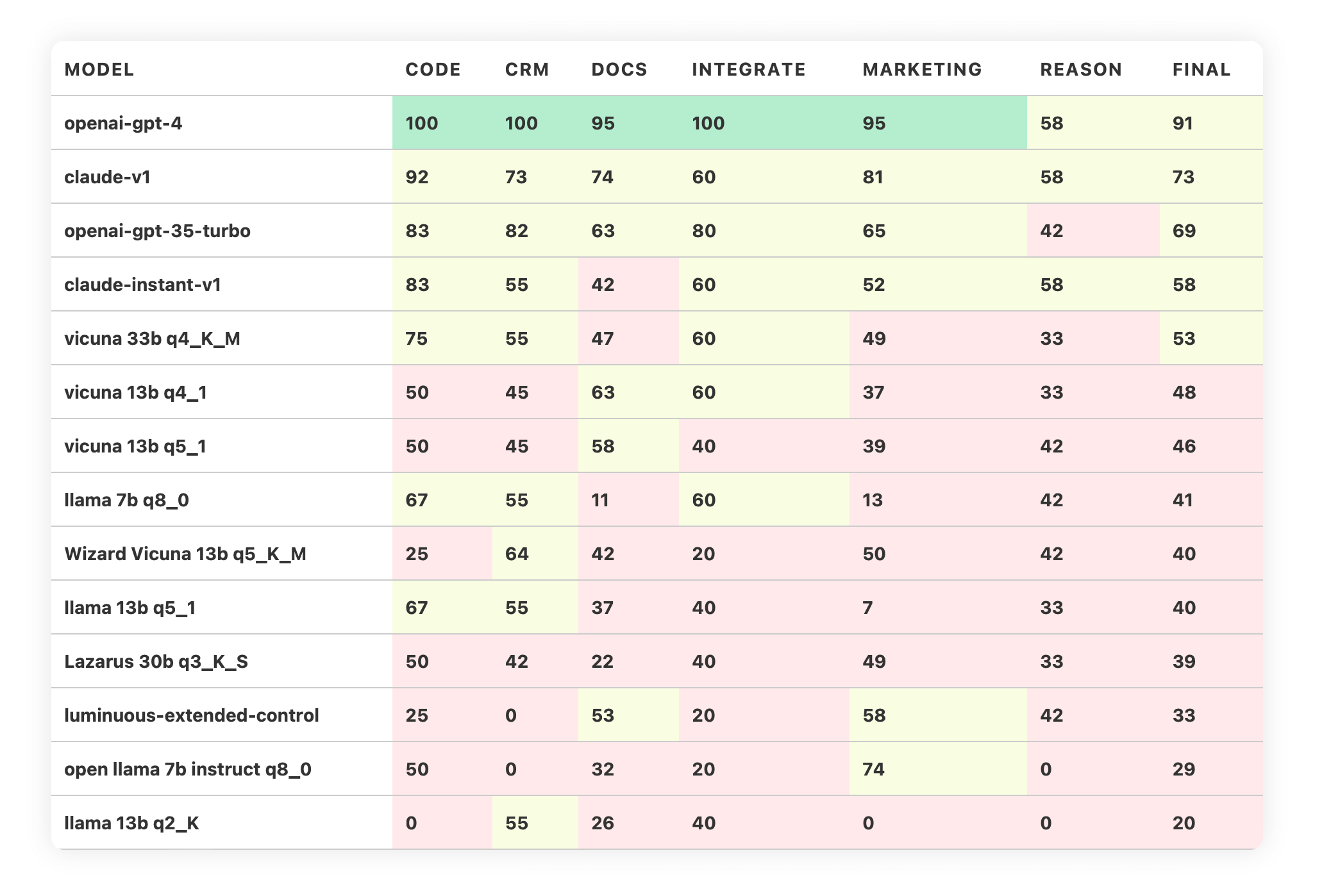
LLM Product Leaderboard: Benchmarks for building and shipping products ...
www.trustbit.tech

Hugging Face Released Open LLM Leaderboard v2 | LLM Explorer Blog
llm-explorer.com

Explained LLM Leaderboard - 2024 - GeeksforGeeks
www.geeksforgeeks.org

The Big Benchmarks Collection - a open-llm-leaderboard Collection
huggingface.co
🎥 Видео
LLM Benchmarks: HELM, Open LLM Leaderboard, MMLU Explained
YouTube • January 5, 2026 • 05:31
Dive into the world of Large Language Model (LLM) benchmarks! In this video, we'll explore key benchmarks like HELM, the Open LLM Leaderboard, and MMLU, understanding how they evaluate and rank LLMs. Learn about the different methodologies, metrics, and what they reveal about the strengths and weaknesses of various models. Whether you're an AI ...
7 Popular LLM Benchmarks Explained [OpenLLM Leaderboard & Chatbot Arena]
YouTube • January 9, 2024 • 05:50
Check out my website here! https://leaderboard.bycloud.ai/ In this video, I will be going through and explain the benchmarks for Chatbot Arena & Open LLM leaderboard. These are more general benchmarks for text-based LLMs, so HumanEval is not here. Let me know any other benchmarks you want me to explain in the future! [Chatbot Arena] https ...
LLM Benchmarks: MMLU, HellaSwag, & Why They Matter
YouTube • January 9, 2026 • 00:49
Is your LLM smart... or just pretending? MMLU and HellaSwag are key benchmarks for evaluating LLM performance, but understanding their nuances and evaluation metrics is crucial. This video breaks down these essential tools for any engineer working with large language models. #llm, #ai, #machinelearning, #nlp, #artificialintelligence, # ...
What Do LLM Benchmarks Actually Tell Us? (+ How to Run Your Own)
YouTube • December 2, 2024 • 30:56
Interpreting and running standardized language model benchmarks and evaluation datasets for both generalized and task specific performance assessments! Resources: lm-evaluation-harness: https://github.com/EleutherAI/lm-evaluation-harness lm-evaluation-harness setup script: https://drive.google.com/file/d/1oWoWSBUdCiB82R-8m52nv_-5pylXEcDp/view ...
Ultimate Guide to LLM Benchmarks: MMLU, HellaSwag, MBPP, GSM-8K, ARC Challenge & More!
YouTube • June 5, 2024 • 16:27
In this video, we dive deep into the most important LLM benchmarks, including: MMLU (Massive Multitask Language Understanding), HellaSwag (Harder Endings, Longer contexts, and Low-shot Activities for Situations With Adversarial Generations), ARC Challenge (AI2 Reasoning Challenge), Winogrande, MBPP (Massive Multi-Task Programming Problems), GSM ...
Open-LLM Leaderboard 2.0-New Benchmarks from HuggingFace
YouTube • July 19, 2024 • 23:39
Learn about the Open LLM Leaderboard 2.0 by HuggingFace! Check out new benchmarks, top models, and the implications for the AI community. 🌟 ⭐️What You'll Learn: - The importance of a standardized LLM leaderboard 🏆 - Challenges in comparing different language models 🤔 - New benchmarks introduced: MMLU Pro, GPQA, MUSR, MATH, IFEval ...