Результаты для "open llm leaderboard"
Open LLM Leaderboard - Hugging Face
https://huggingface.co/open-llm-leaderboard
This is the hub organisation maintaining the Open LLM Leaderboard. In this space you will find the dataset with detailed results and queries for the models on ...
Open LLM Leaderboard 2025 - Vellum AI
https://www.vellum.ai/open-llm-leaderboard
This AI leaderboard shows comparison of capabilities, price and context window for leading commercial and open-source LLMs, based on the benchmark data ...
Open LLM Leaderboard Archived - Hugging Face
https://huggingface.co/spaces/open-llm-leaderbo...
Open LLM Leaderboard Archived. Comparing Large Language Models in an open and reproducible way. Failed to fetch. © 2024 Hugging Face - Open LLM Leaderboard ...
Open source LLMs leaderboard : r/LocalLLaMA - Reddit
https://www.reddit.com/r/LocalLLaMA/comments/1m...
15 июл. 2025 г. ... Open LLM leaderboard is archived, what are the alternatives? r/LocalLLaMA icon. r/LocalLLaMA. • 8mo ago ...
Open-LLM-Leaderboard: Open-Style Question Evaluation - GitHub
https://github.com/VILA-Lab/Open-LLM-Leaderboard
We introduce the Open-LLM-Leaderboard to track various LLMs' performance on open-style questions and reflect their true capability.
LLM Leaderboard - Comparison of over 100 AI models from OpenAI ...
https://artificialanalysis.ai/leaderboards/models
Comparison and ranking the performance of over 100 AI models (LLMs) across key metrics including intelligence, price, performance and speed (output speed ...
Open LLM Leaderboard 2025 - Open Source AI Models
https://llm-stats.com/leaderboards/open-llm-lea...
Open LLM Leaderboard ; OpenAI logo OpenAI ; Anthropic logo Anthropic ; Google logo Google ; Meta logo Meta ; Qwen logo Qwen
LLM Model Selection Made Easy: The Most Useful Leaderboards for ...
https://dev.to/suzuki0430/llm-model-selection-m...
15 мар. 2025 г. ... Open LLM Leaderboard ... This is the most well-known leaderboard for comparing open-source models. It allows filtering based on criteria such as ...
Open LLM Leaderboard: Benchmarks, Model Types & Filters ...
https://obot.ai/resources/learning-center/open-...
6 июн. 2024 г. ... The Open LLM Leaderboard, hosted on Hugging Face, evaluates and ranks open-source Large Language Models (LLMs) and chatbots.
[2406.07545] Open-LLM-Leaderboard: From Multi-choice to ... - arXiv
https://arxiv.org/abs/2406.07545
11 июн. 2024 г. ... Consequently, we introduce the Open-LLM-Leaderboard to track various LLMs' performance and reflect true capability of them, such as GPT-4o/4/3.5 ...
🖼️ Изображения
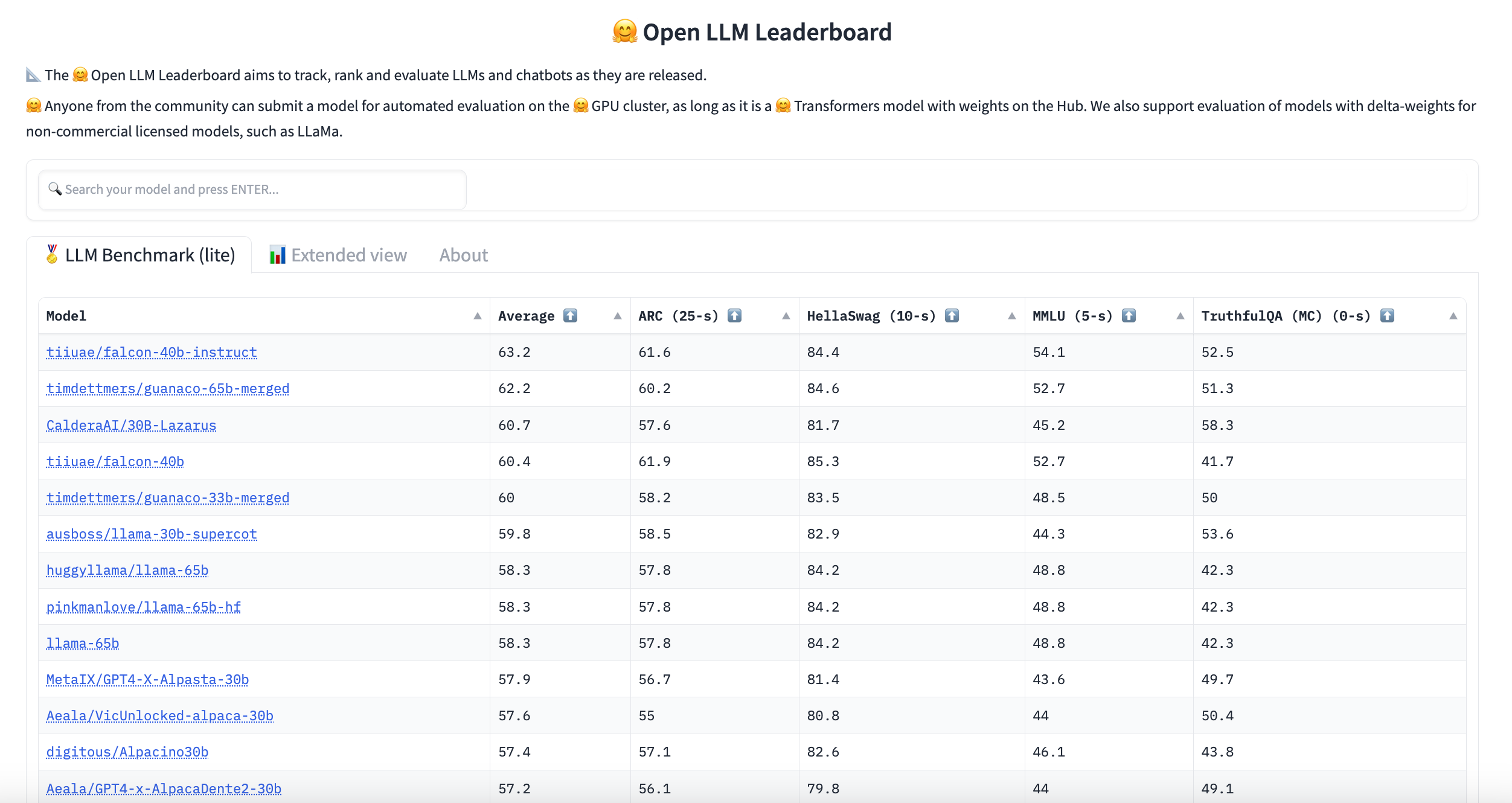
Open-Source Text Generation & LLM Ecosystem at Hugging Face
huggingface.co

Open LLM Leaderboard - HuggingFace推出的开源大模型排行榜单 | AI工具集
ai-bot.cn
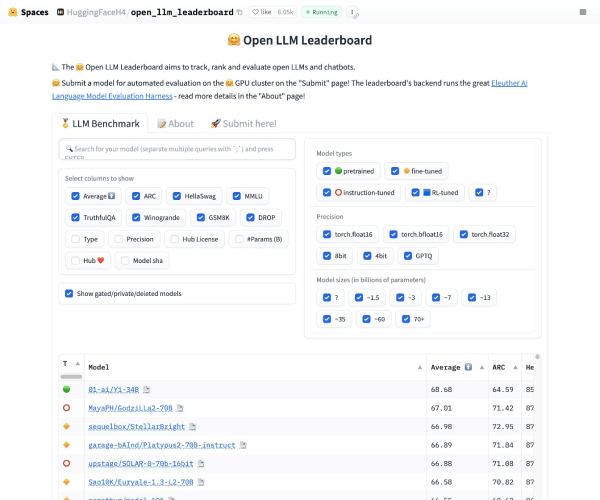
Hugging Face推出Open LLM Leaderboard:大型语言模型性能评估平台 | AI工具箱
ai-kit.cn

Open PL LLM Leaderboard - ranking otwartych LLM testowanych na języku ...
aitrends.pl
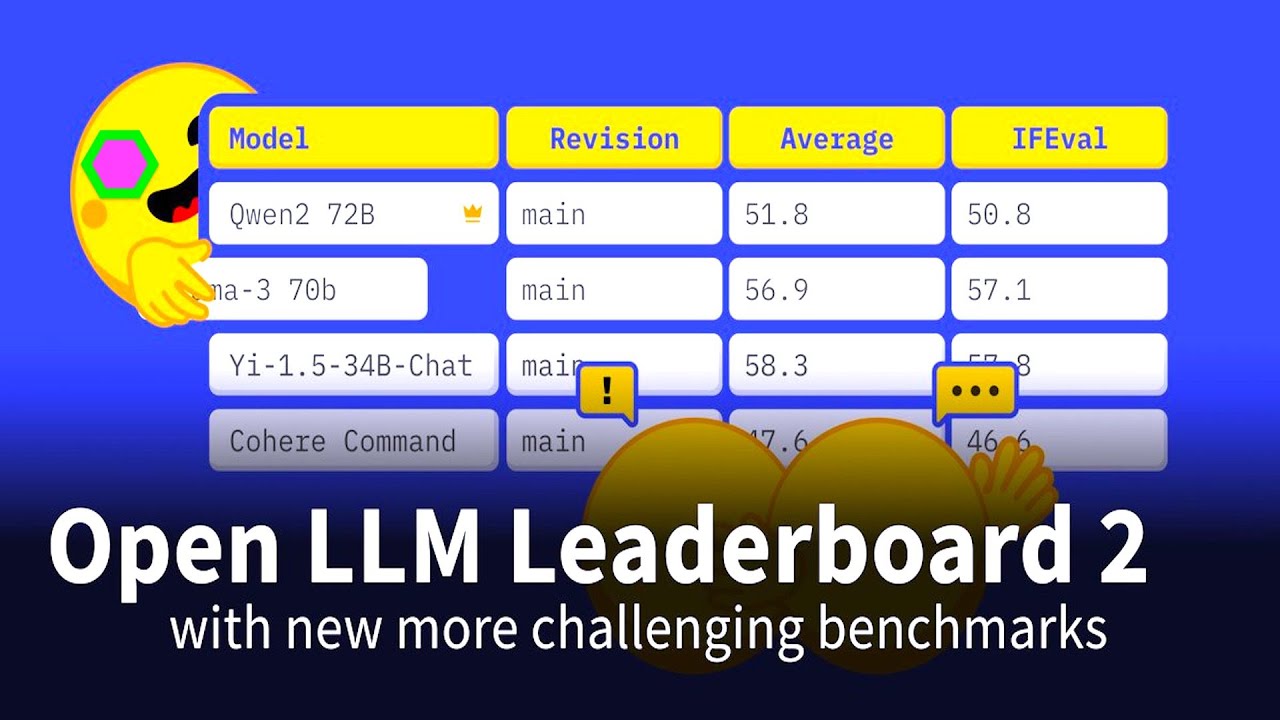
Open LLM Leaderboard 2 released! Qwen 2-72B Dominates! - open-source ...
www.artofsm.art

开源LLM微调训练指南:如何打造属于自己的LLM模型_api for open llm-CSDN博客
blog.csdn.net

Open LLM Leaderboard - HuggingFace推出的开源大模型排行榜单 | AI工具集
ai-bot.cn

Open LLM Leaderboard - a Hugging Face Space by open-llm-leaderboard
huggingface.co

Hugging Face Released Open LLM Leaderboard v2 | LLM Explorer Blog
llm-explorer.com
🎥 Видео
Open-LLM Leaderboard 2.0-New Benchmarks from HuggingFace
YouTube • July 19, 2024 • 23:39
Learn about the Open LLM Leaderboard 2.0 by HuggingFace! Check out new benchmarks, top models, and the implications for the AI community. 🌟 ⭐️What You'll Learn: - The importance of a standardized LLM leaderboard 🏆 - Challenges in comparing different language models 🤔 - New benchmarks introduced: MMLU Pro, GPQA, MUSR, MATH, IFEval ...
7 Popular LLM Benchmarks Explained [OpenLLM Leaderboard & Chatbot Arena]
YouTube • January 9, 2024 • 05:50
Check out my website here! https://leaderboard.bycloud.ai/ In this video, I will be going through and explain the benchmarks for Chatbot Arena & Open LLM leaderboard. These are more general benchmarks for text-based LLMs, so HumanEval is not here. Let me know any other benchmarks you want me to explain in the future! [Chatbot Arena] https ...
FALCON LLM - NEW KING on OPEN LLM LEADERBOARD!
YouTube • May 27, 2023 • 12:07
In this video, we cover the new FALCON-40B LLM from TII, UAE. This model is able to beat all the open-source models on the OPEN LLM Leaderboard by the hugging face. In this video, we will not only cover the model but I will also show you how to run this with Google Colab CONNECT ☕ Buy me a Coffee: https://ko-fi.com/promptengineering |🔴 ...
Comparing Open Source and Proprietary LLM's (Leaderboard Ranking Demo)
YouTube • December 23, 2024 •
Comparing Open Source and Proprietary LLM's (Leaderboard Ranking Demo)
What Do LLM Benchmarks Actually Tell Us? (+ How to Run Your Own)
YouTube • December 2, 2024 • 30:56
Interpreting and running standardized language model benchmarks and evaluation datasets for both generalized and task specific performance assessments! Resources: lm-evaluation-harness: https://github.com/EleutherAI/lm-evaluation-harness lm-evaluation-harness setup script: https://drive.google.com/file/d/1oWoWSBUdCiB82R-8m52nv_-5pylXEcDp/view ...
Chinese AI models storm Hugging Face's Open LLM Leaderboard!
YouTube • June 26, 2024 • 09:38
Open LLM Leaderboard 2 released! Evaluating LLMs is not easy. Finding new ways to compare LLM fairly, transparently, and reproducibly is important! Benchmarks are not perfect, but they give us a first understanding of how well models perform and where their strengths are. What's new?! 📈 New benchmarks with MMLU-Pro, GPQA, MuSR, MATH, IFEval ...